数据来源
从女儿心心出生开始,我们就通过各种方式记录她的各种信息:睡眠记录,吃药记录,体温记录,换尿布记录,哺乳记录等等。毕竟,处于忙乱状态的人们是很难精确地回忆各种数字的,特别是在体检时面对医生的询问时。大部分父母无法准确回答小孩上周平均的睡眠时间,或者平均的小便次数,这在很多时候会影响医生的判断。
我和我老婆的手机上都安装了宝宝生活记录(Baby Tracker)(这里强烈推荐一下,免费版就很好用,不过界面下方有个讨厌的广告,我自己买了无广告的Pro版本),这样心心的每次活动我们都会记录下来,很有意思的是这个APP的数据可以以CSV格式导出(这个太棒了!),而且它自身就可以生成各种的报告,报告还可以以PDF格式导出并发送给其他应用。
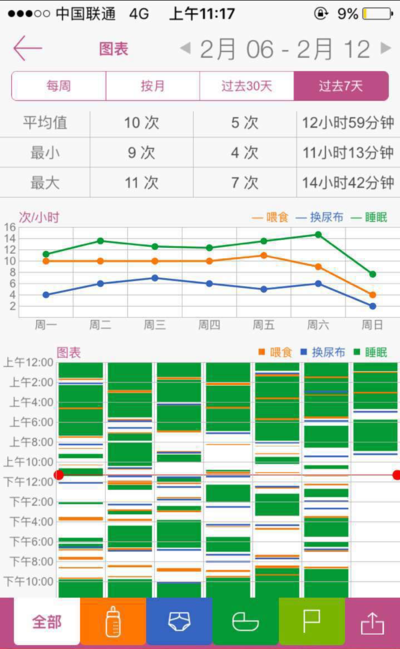
有了现实世界中的一组数据 – 我们记录的差不多100天的数据,而且正好我最近在复习D3相关的知识,正好可以用来做一些有趣的练习。
数据准备
从Baby Tracker导出的数据是一些CSV文件组成是压缩包,解压之后大致结果是这样的:
- 哺乳记录
- 睡眠记录
- 换尿布记录
- 喂药/体温记录
- 里程碑记录
我就从最简单换尿布数据记录开始吧。我们首先需要将数据做一些清洗和归一化,这样方便前端页面的计算和渲染。数据处理我一般会选择Python+Pandas的组合,只需要写很少的代码就可以完成任务。
python + pandas
原始数据看起来是这样的:
name,date,status,note
心心,2016/11/13 17:00,嘘嘘
心心,2016/11/13 19:48,嘘嘘+便便
心心,2016/11/13 22:23,便便
心心,2016/11/14 00:19,便便,一点点,感觉很稀,穿厚点
心心,2016/11/14 04:33,嘘嘘
心心,2016/11/14 09:20,便便
心心,2016/11/14 11:33,便便
心心,2016/11/14 16:14,便便
心心,2016/11/14 21:12,嘘嘘+便便
心心,2016/11/14 23:12,嘘嘘+便便
心心,2016/11/15 00:32,嘘嘘+便便,有点稀
心心,2016/11/15 03:45,干爽
心心,2016/11/15 07:06,嘘嘘
心心,2016/11/15 10:30,嘘嘘+便便
为了方便展示,我需要将数据统计成这样:
date,urinate,stool
2016-11-13,2,2
2016-11-14,3,6
2016-11-15,6,8
我不关心每一天不同时刻换尿布的事件本身,只关心每天中,大小便的次数分布,也就是说,我需要这三项数据:日期,当天的小便次数,当天的大便次数。这个用pandas很容易就可以整理出来了,status字段的做一个微小的函数转换(当然可以写的更漂亮,不过在这里不是重点,暂时跳过):
import numpy as np
import pandas as pd
diaper = pd.read_csv('data/diaper_data.csv', usecols=['date', 'status'])
diaper['date'] = pd.to_datetime(diaper['date'], format='%Y/%m/%d %H:%M')
diaper.index=diaper['date']
def mapper(key):
if key == '嘘嘘':
return pd.Series([1, 0], index=['urinate', 'stool'])
elif key == '便便':
return pd.Series([0, 1], index=['urinate', 'stool'])
else:
return pd.Series([1, 1], index=['urinate', 'stool'])
converted = diaper['status'].apply(mapper)
diaper = pd.concat([diaper, converted], axis=1)
grouped = diaper.groupby(pd.TimeGrouper('D'))
result = grouped.aggregate(np.sum)
result.to_csv('data/diaper_normolized.csv')
这里的pd.TimeGrouper('D')表示按天分组。好了,存起来的diaper_normolized.csv文件就是我们想要的了,接下来就看如何可视化了。
可视化
仔细看一下数据,自然的想法是横坐标为日期,纵坐标为嘘嘘/便便的次数,然后分别将嘘嘘和便便的绘制成曲线即可。这个例子我使用D3来做可视化的工具,D3本身的API层次比较偏底层,这点和jQuery有点类似。
尝试1 - 曲线图
最简单的情况,只需要定义两条线条函数。
var valueline = d3.svg.line()
.x(function(d) {
return x(d.date);
})
.y(function(d) {
return y(d.urinate);
});
var stoolline = d3.svg.line()
.x(function(d) {
return x(d.date);
})
.y(function(d) {
return y(d.stool);
});
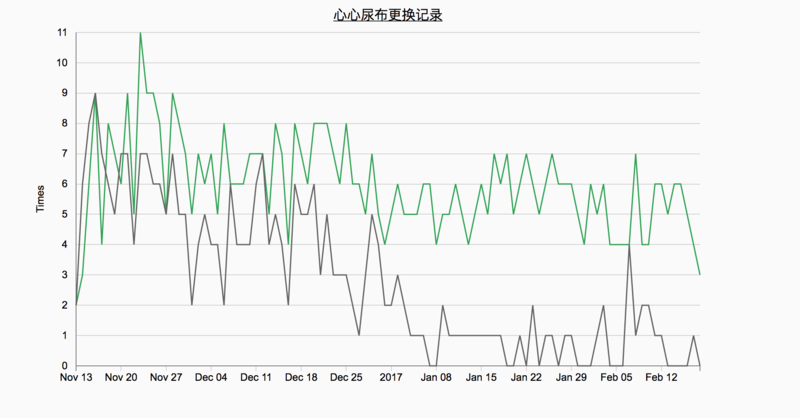
可以看到,直接将点连接起来,线条的拐点看起来会非常的尖锐。这个可以通过使用D3提供的插值函数来解决,比如采用basis方式插值:
var valueline = d3.svg.line()
.interpolate('basis')
.x(function(d) {
return x(d.date);
})
.y(function(d) {
return y(d.urinate);
});
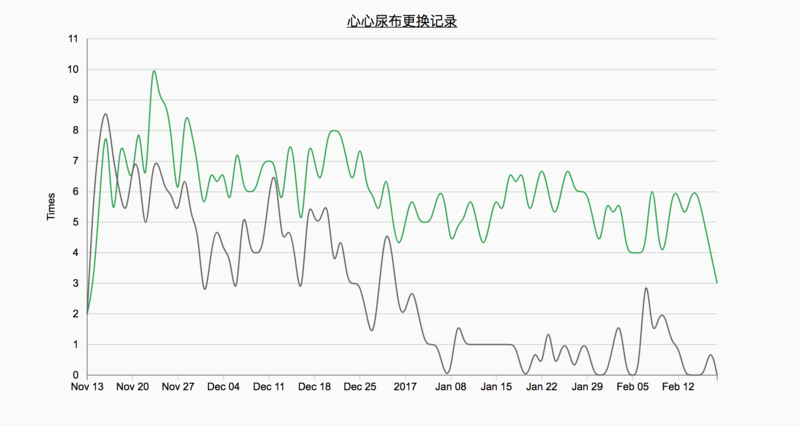
曲线图倒是看起来比较简单,可以看出基本的走势。比如新生儿阶段,大小便的次数都比较多,随着月龄的增长,呈现出了下降的趋势,而且便便次数降低了很多。
尝试2 - 散点图(气泡图)
曲线图看起来并不是太直观,我们接下来尝试一下其他的图表类型。比如散点图是一个比较好的选择:
svg.selectAll("dot")
.data(data)
.enter().append("circle")
.attr('stroke', '#FD8D3C')
.attr('fill', '#FD8D3C')
.attr('opacity', ".7")
.attr("r", function(d) {return 3;})
.attr("cx", function(d) { return x(d.date); })
.attr("cy", function(d) { return y(d.urinate); });
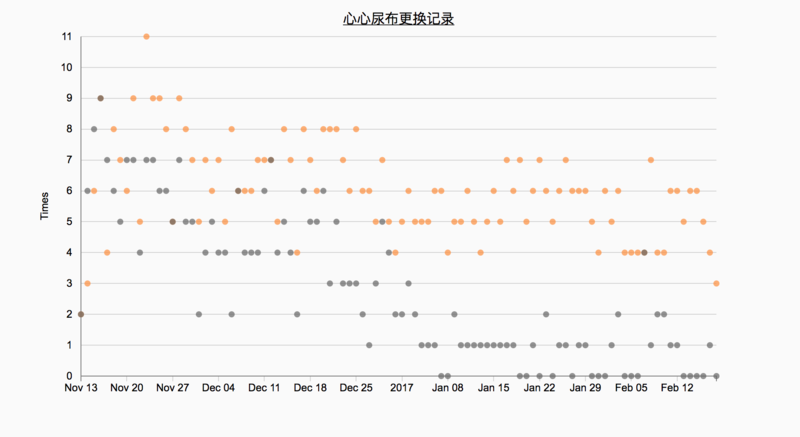
这里还使用了不同的颜色来区分嘘嘘和便便,但是信息强调的也不够充分。这时候可以通过尺寸的不同,色彩饱和度的差异再次强调各个点之间的对比:
svg.selectAll("dot")
.data(data)
.enter().append("circle")
.attr('stroke', '#FD8D3C')
.attr('fill', '#FD8D3C')
.attr('opacity', function(d) {return d.urinate * 0.099})
.attr("r", function(d) {return d.urinate;})
.attr("cx", function(d) { return x(d.date); })
.attr("cy", function(d) { return y(d.urinate); })
.on("mouseover", function(d) {
div.html(formatTime(d.date) + ", 嘘嘘: " + d.urinate + "次")
.style("left", (d3.event.pageX) + "px")
.style("top", (d3.event.pageY - 28) + "px")
.style("opacity", .9)
.style("background", "#FD8D3C");
})
.on("mouseout", function(d) {
div.style("opacity", 0);
});
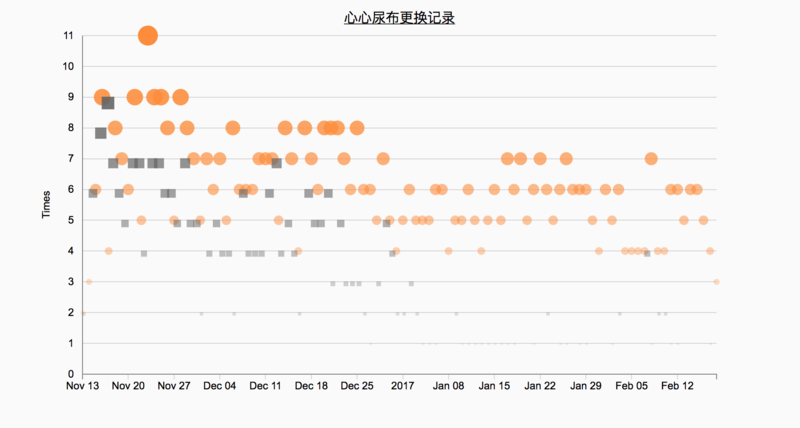
此处的圆的半径与嘘嘘次数相关,圆的透明度也和嘘嘘的次数相关,这样从不同的视觉编码上重复强调数据的差异,效果比单纯的曲线图和散点图会更好一些。
一点理论
数据可视化过程可以分为这样几个步骤:
- 明确可视化的目的
- 数据获取
- 数据预处理
- 选择合适的图表
- 结果呈现
当然,可视化本身就是一个需要不断迭代的过程,步骤的2-5可能会经过多次迭代和修正:比如在呈现之后发现有信息没有充分展现,则需要回退到图表选择上,而不同的图表需要的数据又可能会有不同,我们可能需要又回到数据预处理、甚至数据获取阶段。
选择合适的图表
对于新手而言,图表的选择是非常困难的。同样的数据集,用不同的图表展现,效果会有很大差异。另一方面,对于手头的数据集,做何种预处理并以不同的角度来展现也同样充满挑战。
不过好在已经有人做过相关的研究,并形成了一个非常简便可行的Matrix:
通过这个Martix,你可以根据变量的数量,变量的类型很方便的选取合适的图表格式。这个表可以保证你不出大的差错,最起码可以很清晰的将结果展现出来。
视觉编码(Visual Encoding)
视觉编码,简而言之就是将数据映射为可视化的元素,这些元素可以帮助人们很快的区分出数据的差异。比如通过颜色的不同来区分分类型元素(亚太区收入,亚洲区收入),通过长度的不同来表示数量的不同等等。视觉编码有很多不同的元素:
- 位置
- 形状(体积)
- 纹理
- 角度
- 长度
- 色彩
- 色彩饱和度
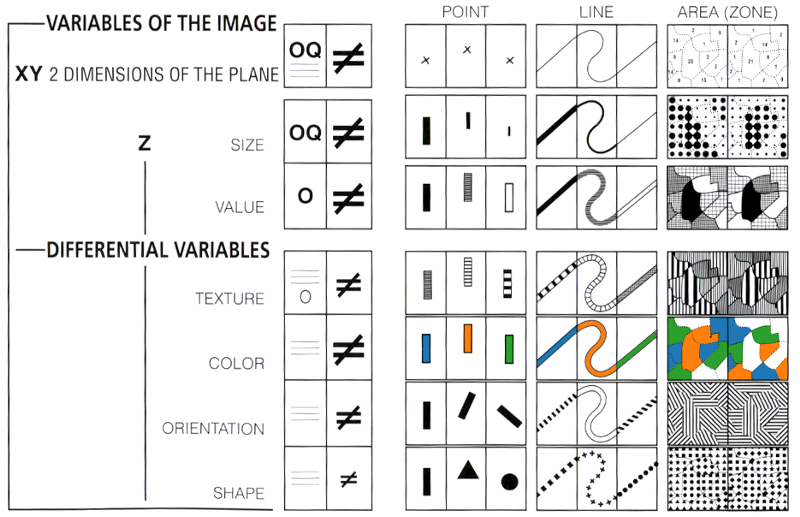
Within the plane a mark can be at the top or the bottom, to the right or the left. The eye perceives two independent dimensions along X and Y, which are distinguished orthogonally. A variation in light energy produces a third dimension in Z, which is independent of X and Y…
The eye is sensitive, along the Z dimension, to 6 independent visual variables, which can be superimposed on the planar figures: the size of the marks, their value, texture, color, orientation, and shape. They can represent differences (≠), similarities (≡), a quantified order (Q), or a nonquantified order (O), and can express groups, hierarchies, or vertical movements.
而且,人类对这些不同元素的认知是不同的,比如人们更容易辨识位置的不同,而比较难以区分饱和度的差异。这也是为什么大部分图表都会有坐标轴和标尺的原因(当然,还有网格),而像饼图这样的图形则很难让读者从形状上看出不同部分的差异。
Jock Mackinlay发表过关于不同视觉编码优先级的研究:
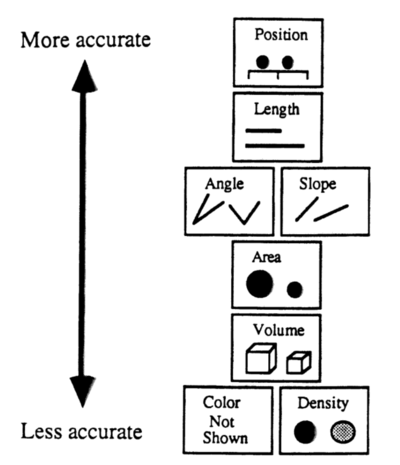
越靠近上面的元素,在人眼所能识别的精度就越高。在图表类型的选取上,也需要充分考虑这些研究的成果,选取合理的视觉编码。
正如前面所说,可视化是一个不断迭代的过程,要将同样的信息展现出来,可能需要尝试不同的视觉编码的组合,比如:
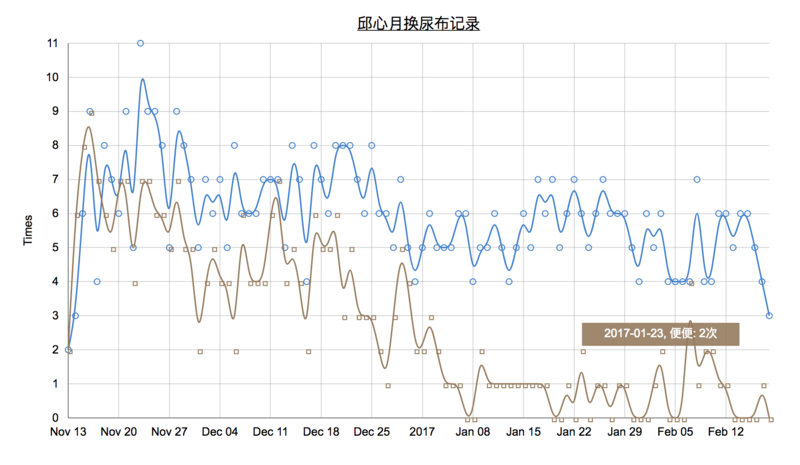
上面几个图表对应的代码在这里,下一篇我们来看看数据可视化的其他知识。