###background
元旦放假前,team的同事们想要一起学习一些技术,然后一起做些小东西,有人提到将物理墙上的卡,通过手机拍照,识别出其中的卡号,然后与电子墙同步状态。这是一个非常有意思的主题,会涉及到很多方面的知识,其实有好几个topic,只不过我对人工智能/机器学习等比较有兴趣而已,所以就先自己研究下。
几天下来,关于数字识别的基本的流程已经清晰了,关于图片的预处理及边界标定等都差不多就绪了,剩下比较重要的是识别本身了。在这个过程中,遇到了一些很有意思的算法,我自己也花费了好几天才弄明白,所以整理了一下,这一篇先介绍下第一个,也是最简单最好用的KNN算法。
###K-nearest-neighbour简介
KNN是机器学习中最简单的一种无值守的学习方法,但是在实际场景中,效果却经常非常好。一般来说,在样本较多,分布均匀的空间中,KNN会收到很好的效果。但是由于KNN会计算空间中的每个点与需要标定的点的距离(甚至需要计算额外的权重信息),所以计算量会较大。
假设所有的点都均匀的分布在一个平面内,此时的平面密度(单位范围内的点的个数)非常大,而每个子平面内的点的分布与所有点在整个平面内的分布相当。在子平面S中,有一个点Y,则离点X(to be classified)最近的Y很可能与Y同在子平面S中。
比如取出空间中与X距离最近的有5个点(K=5),其中3个属于C1类,2个属于C2类,则根据少数服从多数原则,X点被归类为C1.这样的一个缺点就是如果空间内的点分布不均匀,那么会有一些误差,如果上面这个场景经常出现,那么分类会越来越偏离(有一个偏心的硬币,投掷100,000次,有90,000次正面)。这样就有引入了对KNN的另一个扩展方式,加入权重的KNN:
当然这种形式的KNN不是很精确,由此引申出了带权重的KNN:可以为每个点都赋予一个权值,每个权值与新的点X的距离有关,通常会取距离的倒数,这样与X最近的点有较高的权重,而较远的点具有较低的权重,这样在投票(voting)阶段可以相对的提高精确度
###KNN的一个python版本示例
####背景(高斯分布)
import random
def gauss_list(mu, sigma, count=100):
return [random.gauss(mu, sigma) for _ in range(count)]
生成一个随机数数组,数组中的元素符合高斯分布,如
ran = gauss_list(-2, 1, 10)
print ran
运行结果如下:
[-1.3277188634970218, -2.1034487392146817, -0.5924407591392826, -0.30376289085064045, -2.191337071105794, -1.9781081550478732, -3.7937155472105673, -2.538102349796847, -1.3728510997834549, -2.766669661625006]
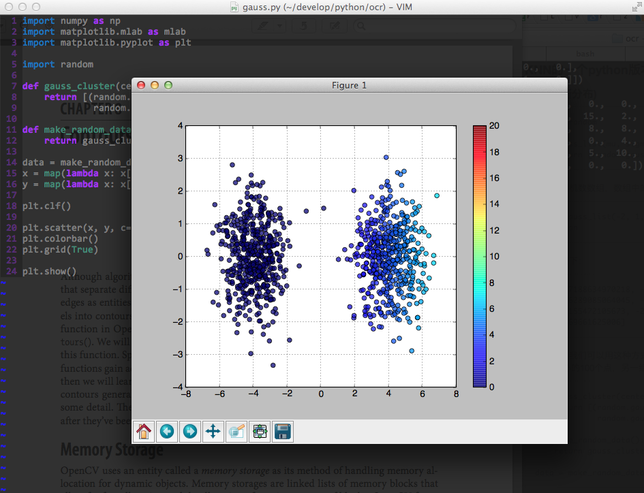
更进一步,我们可以用这种方式生成平面中的一些点,这些点可以根据分布情况分为两组,一组是以(-4,0)为重心的500个点,另一组是以(4,0)为重心的500个点:
def gauss_cluster(center, stdDev, count=500):
return [(random.gauss(center[0], stdDev),
random.gauss(center[1], stdDev)) for _ in range(count)]
def make_random_data():
return gauss_cluster((-4, 0), 1) + gauss_cluster((4, 0), 1)
data = make_random_data()
####绘制高斯分布
data = make_random_data()
x = map(lambda x: x[0], data)
y = map(lambda x: x[1], data)
plt.clf()
plt.scatter(x, y, c=x, vmin=0, vmax=20, s=35, alpha=0.75)
plt.colorbar()
plt.grid(True)
plt.show()
通过使用matplotlib的绘图功能,将make_random_data生成的点通过图形的方式展现,效果更加直观,图中的两个点集分别表示两个不同的类别。
####KNN
我们定义KNN分类器,其中两点间的距离按照欧氏公式来求,先计算点集中离x点最近的k个点,然后取得对应的k个label,再按照label个数球max。
比如k=5时,求的的label集合为[‘O’, ‘O’, ‘A’, ‘A’, ‘A’],则我们认为这个点应该被分类为A(少数服从多数)。
def euclidean_distance(x, y):
return math.sqrt(sum([(a-b)**2 for (a,b) in zip(x,y)]))
def makeKNNClassifier(data, labels, k, distance):
def classify(x):
closestPoints = heapq.nsmallest(k, enumerate(data),
key=lambda y: distance(x, y[1]))
closestLabels = [labels[i] for (i, pt) in closestPoints]
return max(set(closestLabels), key=closestLabels.count)
return classify
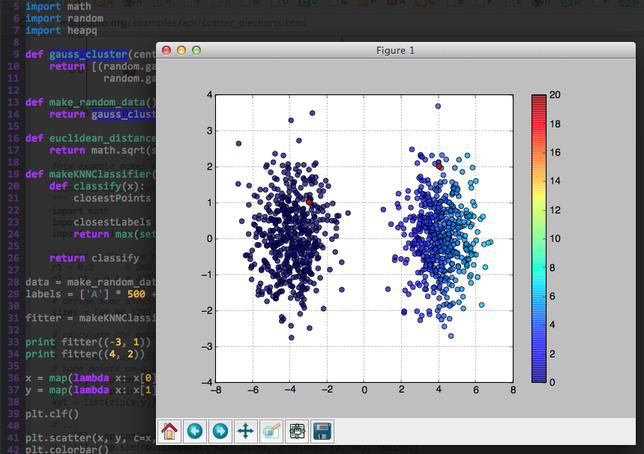
####测试一下 创建1000个随机点,前500个分类为A(Apple),后500个分类为O(Orange),k值为3。
data = make_random_data()
labels = ['A'] * 500 + ['O'] * 500
fitter = makeKNNClassifier(data, labels, 3, euclidean_distance)
print fitter((-3, 1))
print fitter((4, 2))
图中的两个红色的点分别为P1(-3, 1)和P2(4, 2)。它们都已经被正确的分类。