如何修复一个缺陷
如果给我一个小时来修复一个缺陷,我会花50分钟来写测试,用剩下的10分钟来改代码
– 本来是一句模仿爱因斯塔的名言,结果发现爱因斯坦并没有说过……
你确定这是个缺陷吗?
下午2点,你喝下了一杯拿铁,它可以保证你在接下来的几个小时内保持清醒。突然,一位QA同事急匆匆的走了过来,从他的表情你就看出来事情不妙。果然,他告诉你SIT环境有个重大缺陷,如果不及时修复,好几个测试流程都不能进行。没错,你在还没有完全搞清楚发生了什么值钱,就莫名其妙的突然变成为了系统中一个“blocker”。
这位QA的神情和他对事情的描述让你不自觉的受到了一些感染,你也开始有点焦虑。你想要快速切换到IDE下,赶紧复现并修复他描述的问题。毕竟,你可不想成为一个阻塞别人工作的人。
我对你急切的心情表示理解,不过在你实际动手改代码之前,先冷静一下,稍微抑制一下赶紧修复问题的那种冲动。我们来看看在面对如此场景,如何表现的更为专业,以及更加卓有成效。
开始之前
事实上,在开始修复任何一个缺陷之前,你需要确认它确实是一个缺陷。这一点经常为很多新手忽略,从而导致修复缺陷从艺术变成了救火工作。
作为一名靠谱的开发,在真正动手修复之前,你可以做这样一些预先的check:
- 缺陷是不是发生在不受支持的浏览器上?
- 部署之后,有没有清理浏览器缓存?
- 下游系统是不是有计划内更新?
- 确定部署了最新版本吗?(部署之后,有没有机制可以确保SIT是最新版本)
或者你可以当QA宣称他找到了一个缺陷时,你可以反问:“你有没有试着重启浏览器/系统?”。很多情况下,在做了这些检查之后,你发现问题自己就解决了 – 此谓不战而屈人之兵也。
如果事情仅仅到这一步就结束的话,你就可以接着看看medium上的文章或者刷刷知乎什么的。不过有时候,事情就不会这么顺利了。
遗漏掉的需求
不论前期分析的多么完善,在实际项目的行进中,还是会遇到一些遗漏掉的需求点。比如招聘系统中的对留学生通道的考虑,银行系统中的海外信用卡的货币汇率转换等等。有时候,当听完QA的描述后,如果你和团队里的其他人都表示这个功能点是第一次听说,那么不用慌张,这很可能是一个被遗漏掉的需求。
这时候只需要冷静下来,将其记录下来,然后作为正常的Story流程进行即可(排列优先级,kick-off,被拖入in-doing等等)
还真是个缺陷
如果它竟然还不是一个漏掉的需求,承认自己写的代码有缺陷也不是什么丢人的事儿。而且即使是缺陷,也并不意味着需要立即修复。和所有的其他需求那样,缺陷也应该被分级,并当成一个正常的Story卡流入Backlog。
在实践中,我发现这一点非常关键。很多团队在开发过程进入修复缺陷阶段之后变得各种混乱,其源头也正是来源于此。一个非常糟糕的实践是:某个人负责将测试团队中发现的缺陷分发给指定的人,并一天两次的常规Check是否有所进展。这个貌似高频率反馈的过程可以毁掉团队的敏捷氛围:工作从拉动的方式变成了指派。
正确的做法是:为缺陷建立卡片,并和其他需求卡一起排列优先级,并通过拉动的方式流入开发流程,并像任何一张卡片那样进行kick-off,in-dev,sign-off等。换言之,不要特殊对待缺陷,把它当成普通的需求变更即可。
如何重现
一旦你确定了一个缺陷,并且需要修复它,那么第一件要做的事情自然是重现它。很多时候,重现并不那么容易。在实际项目中,应用可能有各种各样的外部依赖,比如:
- 依赖网络请求来获取数据
- 依赖特定的浏览器(可能是旧版本,也可能是特定浏览器)
- 依赖后端服务正常工作
所有的后端服务的异常都可能导致前端页面上的非预期行为:一个空白页面或者一个有着大红色叉的对话框,上书“找不着对象”等等。这些错误有时候可能会很难复现,或者至少需要一些特别的设置才可以使之发生。
网络异常
网络异常非常常见,而且可以导致各种各样的异常行为。开发中,localhost或者办公室的千兆宽带往往很难看到一些仅仅会在4G或者更慢速网络中会出现的问题。而当多个页面请求中的某一个失败时才会出现的缺陷则更难以复现。
不过,Chrome提供的DevTools可以在很大程度上帮助你(不过你可能需要每隔一个月重新学习下这些Tab的布局和新功能,Chrome的开发团队非常乐于偷偷给DevTools上线一些新功能,并完全破坏掉之前的布局)。
假设你需要调试/复现一个关于loading控件的问题,这个缺陷仅仅在网络极差的情况下才可以复现。你可以使用Chrome自带的throttling来模拟这种极端的网络场景。而有时候,你需要模拟网络完全不可用的状况,可以勾选Offline.
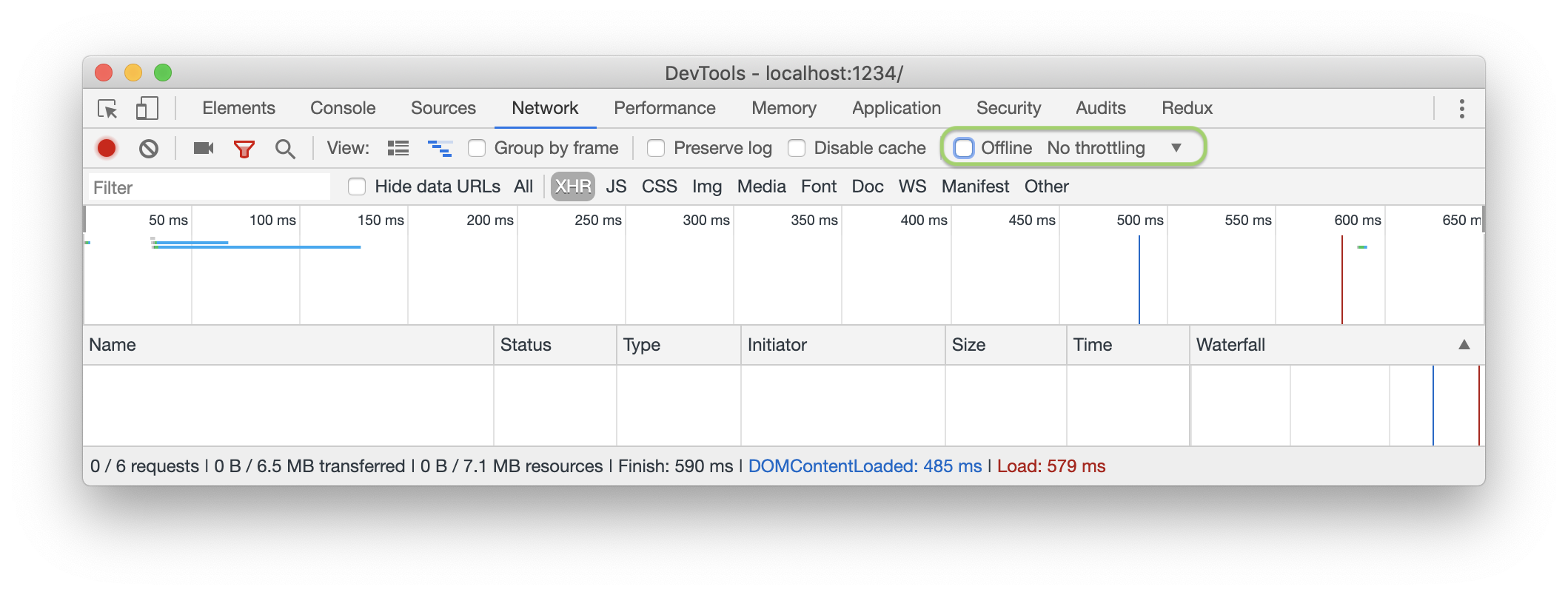
除了这些常规操作之外,你可以以定义黑名单的方式来屏蔽掉一些指定的URL:
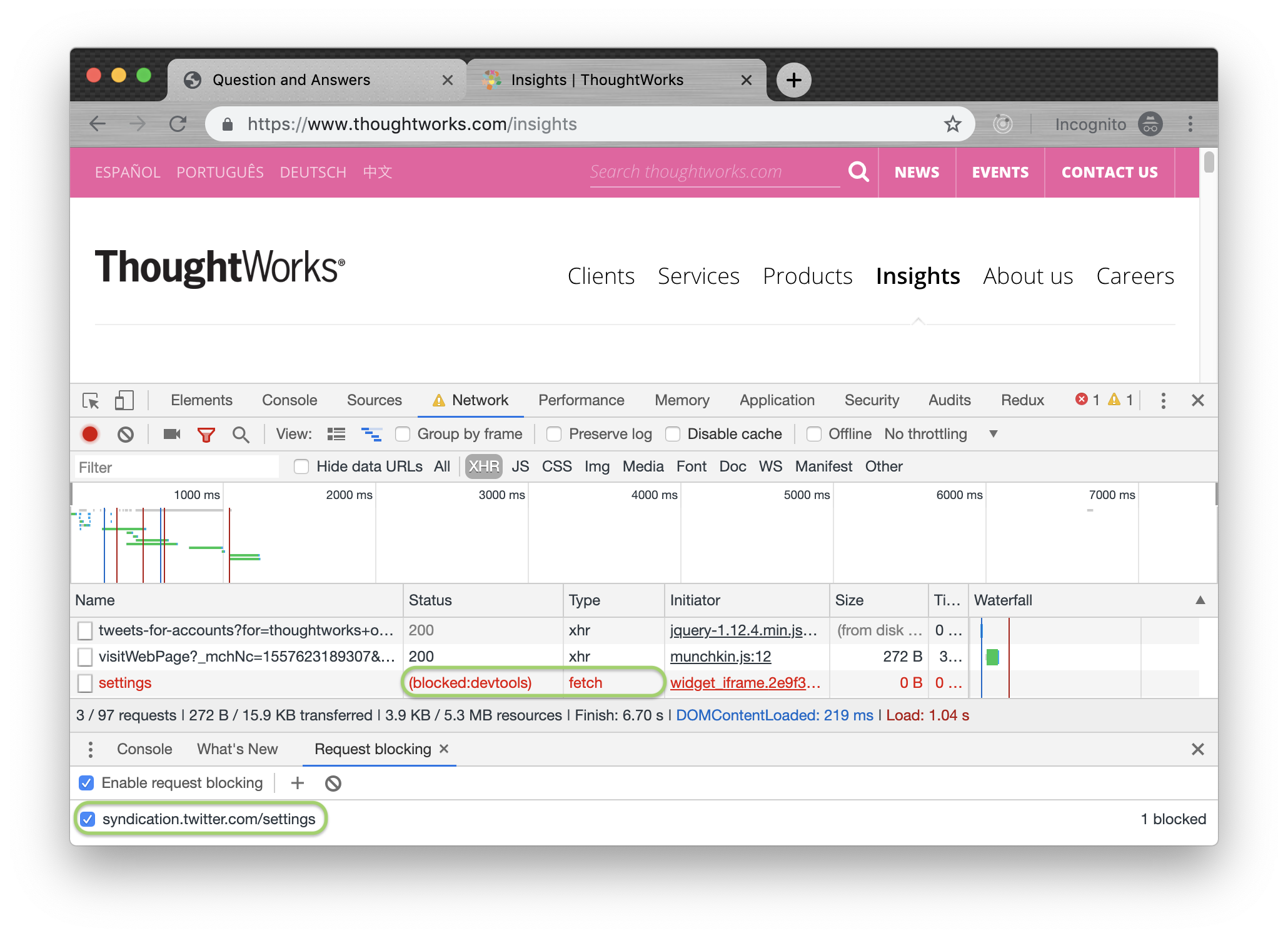
这样,发往黑名单中的URL被屏蔽,这样可以很方便的模拟出改服务不可用的场景。有时候,如果你在开发海外的站点,也可以通过屏蔽特定的URL,比如facebook或者twitter链接来查看该站点在国内的表现。
消除重现缺陷的其他blocker
现实中,大部分实际应用都有多个页面。如果缺陷在第N个页面上,而你每次都需要从第一步导航到第N步。而如果每一步都有一些必填字段要填写,那么要重现这个缺陷,特别是debug的时候就会变成一场噩梦:你修改了一行代码,live-reload自动刷新并将你重定向到第一页,然后你完成所有填写并到达要调试的组件,然后发现本应该是字符串的地方显示的是[Object Object]。
不过,如果你恰好使用React+Redux组合的话,Redux Devtools Extension可以节省你很多时间。通过使用这个插件,你可以将应用的状态导入/导出。
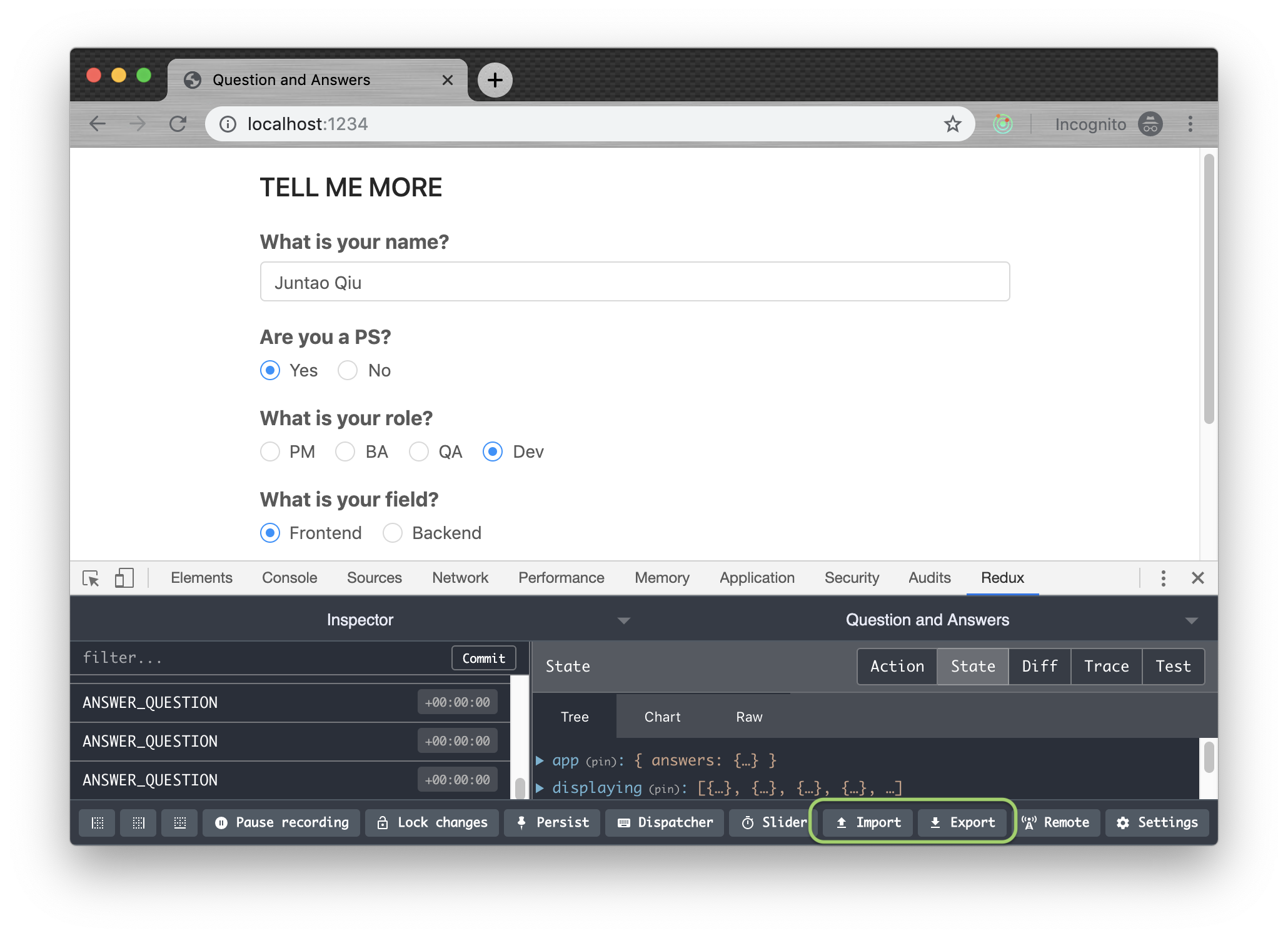
Setup非常容易,只需要在创建redux store的时候加上一行代码即可:
const store = createStore(
reducer, /* preloadedState, */
window.__REDUX_DEVTOOLS_EXTENSION__ && window.__REDUX_DEVTOOLS_EXTENSION__()
);
这样你可以使用该插件将应用在某一时刻的状态导出到本地文件。在导出的文件中,redux-dev-tools会将应用的初始状态和所有发生过的事件(以及事件相关的数据)记录下来,以便重新播放。
当然了,如果你并没有使用React+Redux的组合,很多表单的auto-filler也是可以完成类似动作的。你可能需要花费几分钟来学习如何定义selector以及如何用快捷键来自动填写,不过一旦学会,它就可以节省你很多时间。
寻找根因
根据我的经验,很多缺陷都并非发生在逻辑错误上(比如倒置的if-else,没有跳出的while等)。相反,很多时候错误会发生在错误的mapping,空值的保护不足等场景。
非法数据
实际应用中,每个集成点都潜在的会有这样的问题。比如UI到BFF,BFF到下游的系统等。代码中的很多配置,或者不一致的惯例也会导致类似的问题。
比如,toggle的定义本来是TOGGLE_...形式的,不过后来变成了这样:
features: {
"ADVANCED_SEARCH": false
}
但是代码中有些地方还在使用旧的形式:
{
features.TOGGLE_ADVANCED_SEARCH &&
this.renderAdvancedSearchPanel()
}
另外一个很常见的问题是同一个实体在不同系统中有着不同的名字,或者同一个名字在不同的系统中有着不同的含义。比如Product,Item和OrderItem可能都指向了ShoppingCart,而User,Customer以及Account可能在数据库中是同一条记录等等。然后在集成的时候,前端需要展示一个Customer的列表,但是从后台获取的是一个Account的列表等。
外部依赖
另一个经常会导致问题的是应用外部的依赖。一个应用可能有各式各样的依赖,这些依赖或现或隐,显式的比如系统间调用,浏览器兼容性等,隐式的比如日期/时间等。
多年前,我遇到过一个印象深刻的关于日期的缺陷:
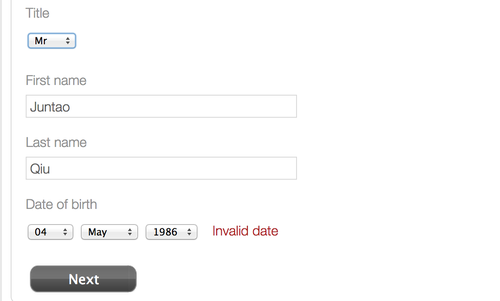
经过好几个小时的分析,最终发现是由夏令时导致的,细节可以参考这篇文章。不过所幸这种依赖可以通过各种各样的工程方式来模拟,比如修改操作系统中的时区来模拟应用所需要运行在的国家/地区,或者将时间调整到某个历史时期来重现特定的问题。
通过上述的各种工具和设置,你终于通过手工操作重现了该缺陷,现在我们来看看如何修复它。
修复
修复缺陷乍看起来好像就是改代码,这也是很多人常犯的一个错误。事实上,修复一个缺陷是实施TDD的一个绝佳机会,它甚至比从零开始开发更容易实施TDD。很多时候,在开发新功能的时候,人们会有各式各样的借口来拒绝实施TDD:诸如降低开发效率,团队能力不匹配等等。
而在修复工作中,通常对输入和输出的定义往往都非常完整:期望某个页面元素的值是$1,200,实际显示的是$1000 – 这天然的就是一个测试用例!
所以修复缺陷的第一步是写一个测试来重现上述的手工重现步骤。当然了,你无须从网络异常开始模拟,而通常可以从当网络异常后,某些数据为空这样的setup来编写测试。
这样做的好处有很多:
- 防止这个缺陷重新混入代码(比如某位同事不小心改坏了代码)
- 对本次修复更有信心
- 便于未来对代码的重构
- 重塑测试套件,使之与测试金字塔更为契合
编写自动化测试
如果只是数据mapping的问题,添加一个用例会非常简单:
it('renders label', () => {
const props = {
label: 'Name'
}
const wrapper = shallow(<InputField {...props} />);
expect(wrapper.find('h6').text()).toBe(props.label);
});
或者测试一个下拉框中正确的消费了预定义的数据结构:
it('renders dropdown', () => {
const props = {
label: 'State',
options: [
{ label: 'VIC', value: 'Victoria' },
{ label: 'WA', value: 'Western Australia' },
{ label: 'SA', value: 'Southern Australia' },
{ label: 'QLD', value: 'Queesland' },
{ label: 'NSW', value: 'New South Wales' }
]
};
const wrapper = shallow(<Dropdown {...props} />);
expect(wrapper.find('<Option>').length).toBe(props.options.length);
});
当然,并非所有缺陷都是这么简单。很多时候,组件间具有某些依赖,或者组件依赖于网络数据等等。比如,容器组件需往往要和后端API进行数据交换,而经常发生问题的是:当后端API更新了schema之后,忘记通知前端。
这时候,独立的测试就没有太大用途了,我们需要某个层次的集成测试。有时候我们甚至需要更高层次的端到端测试(如selenium或者cypress测试)或者契约测试等来确保集成的正确性。
不过通常来说,单元测试和集成测试可以覆盖大部分的场景,端到端级别保留尽可能少而精的测试即可。在单元测试中,你可以通过mock/stub的方式来模拟网络请求/响应。
比如:
it('fetch data from remote', () => {
axios.get = jest.fn().mockImplementation(() => Promise.resolve({data: books}));
});
当然,通常你需要模拟失败和成功两种场景(如果你需要对不同错误码进行不同响应的话,则需要更多的cases)。
it('Fetch data with error', () => {
axios.get = jest.fn().mockImplementation(() => Promise.reject({message: 'Something went wrong'}))
});
如果你需要以端到端的方式来验证某个关键路径,可以使用puppeteer 或者 cypress。
describe('Fancy Application', function() {
it('Add new experience', function() {
cy.visit('https://localhost:1234/experience');
cy.contains('Add').click();
cy.get('.project').type('super')
cy.get('.period').type('10 months')
cy.get('.tech-stack').type('JavaScript')
cy.get('h2').should('contain', 'Worked on project super for 10 months');
});
});
请注意,此处你在通过自动化测试来重现缺陷。如果有了一个失败的测试用例,即你可以通过自动化的方式来重现这个缺陷,那么剩下的事情就会变得简单:修改代码使得测试通过即可。
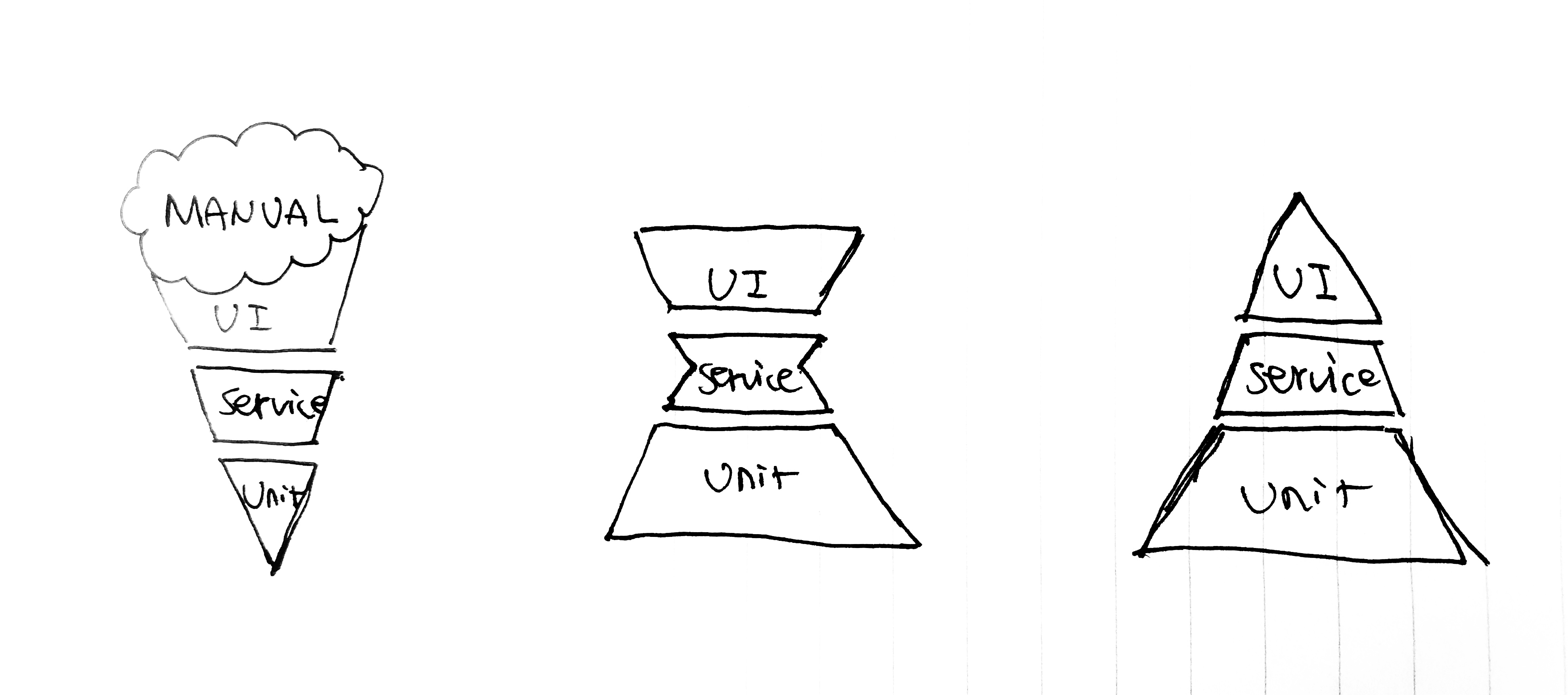
考虑测试金字塔
虽然端到端的测试非常具有诱惑力 – 它会将整个系统串联起来,并告诉你真实的结果。不过它很容易被滥用,太多的端到端测试一方面会导致构建时间过长,另一方面由于真实环境变量太多,大量的端到端测试相比于底层测试往往会比较脆弱。此外,端到端测试非常昂贵,不论是运行时间还是指导开发的debug都不那么开发者友好。
在添加任何额外的端到端测试之前,请优先考虑底层的测试 – 它们运行的更快,更容易帮助开发调试。至于端到端测试,有限的关键路径覆盖对于大部分应用来说就已经足够。
此外,在重构业务代码的同时,也要保持对测试代码的重构:删除重复的、废弃的测试,移动测试到上一层或者下一层,重新分组测试suite等等。每次修复,都尽量让测试套件更符合测试金字塔的原则。
防御式编程
此外,一个在集成中频繁使用的防御式编程可以避免很多潜在的问题,即在系统中,对于输入往往采取不信任的假设。很多场景下,对嵌套数据的存取往往会导致问题,比如shoppingCart[0].item.name.toLowerCase()潜在可能产生若干个can not access xxx of undefined异常。
这时候,你可能不得不编写很多保护逻辑来组织代码:
if(shoppingCart && shoppingCart.length > 0) {
if(shoppingCart[0].item && shoppingCart[0].item.name) {
return shoppingCart[0].item.name.toLowerCase();
}
}
lodash中的_.get可以大大简化类似的场景:
_.get(cart, 'shoppingCart[0].item.name');
另一个常见的技巧是提供in-line的保护机制如:
axios.get().then(response => response.data.products || []);
axios.get().then(response => response.data.products || {});
这种微小的技巧可以节省你花在catch各种运行时异常上的很多时间。
修复之后
通常来说,在修复过程中,你可以通过频繁的mini-showcase(desk check)从QA或者BA那里得到反馈,确保你始终在正确的方向上。
另一个我经常会使用的实践是:在修复完一个大的缺陷后,你可以和团队分享一下修复的过程,比如如何debug,如何复现,根因分析,如何编写测试等等。这样可以帮助别人快速学习到你是如何处理问题的,反过来,你也可能通过团队讨论发现解决问题的新思路。
另外,比修复单一的缺陷更重要的是,这个实践可以帮助团队建立一个良好的、健康的氛围:对于缺陷而言,我们选择直面它,并从中学习 – 而不是指责或者将其分配到指定的人员头上。
小结
当有人告诉你,你的代码有缺陷时,不要慌张。首先确保这确实是一个缺陷(排除测试的打开方式错误,遗漏掉的需求等场景)。通过使用Chrome的DevTools,和一些其他插件,你可以非常高效的模拟一些场景,从而在本地手工重现缺陷。
一旦可以手工重现,你需要编写自动化测试来自动重现。有了测试之后,就可以按照常规的TDD流程来修复。在修复过程中,保持对测试金字塔的关注,必要时还需要重构测试套件,以确保测试和产品代码都处于一个良好的状态。
修复之后,通过对缺陷的分析和修复的过程的分享,让团队从中学习,并鼓励团队其他成员也这么做,使得团队可以在一个安全,健康的氛围中工作。
关于缺陷(defect)和臭虫(bug)的名字,通常来说它们指的是同一个东西。甚至在很多上下文中,你都可以将这两个名词互换而不影响句子整体的意思。不过这里我倾向于使用缺陷(defect),因为bug听着像是问题自己跑到代码中并藏了起来,而缺陷(是指和需求的偏差)则比较中立一些,也比较客观。
P.S. 这篇文章翻译自我自己的同名英文版博客,重写了一部分,另外对缺陷修复的流程上有所修改。