How long does it take for adding a InputBox?
When the Product Owner told you it’s a small change, don’t trust her.
An estimation session
After iteration planing meeting, after all the stories had been walked through, PO turned to you, pretending it was just a impromptu chat, asking how long does it take for adding a input box to one page.
What he described was a “simple” input box for user to enter his/her address along with other personal information and persist to backend.
He even sketched a irregulate box on a whiteboard to illustrate the idea and trying to make it more clear to you. He looked at you, asking you, how long does it take, is that even worthwhile to do a estimation and put it into the backlog or just do it along with some other small card on the wall?
You gut feeling is something important was missing, but you were not too sure what exact it was.
You reckoned for a while, and told PO “It might take, idealy, 5 to 6 days, and if we consider meetings or other activities that would be longer…”
“A week for an InputBox?”, knocking the irregulate box on the whiteboard, the PO looked quite shocked, you could even hear the saved “are you lost your mind?”.
“Well, I meant ideally, that normally will be longer in practice…”
“……”
A big gap like this normally means people are comparing apple to orange, it either the product owner is over-simplifying the problem or the developer is exaggerating it.
The missed details
Because of knowledge barriers and oversimplifing without drill down deep enough into the details, we normally would underestimate things without knowning it. Additionally, if we ignore the resistence in the outside environment, we might easily make mistakes in terms of estimation.
A simple InputBox
From the PO’s point of view, a simple InputBox might be something looks like this:
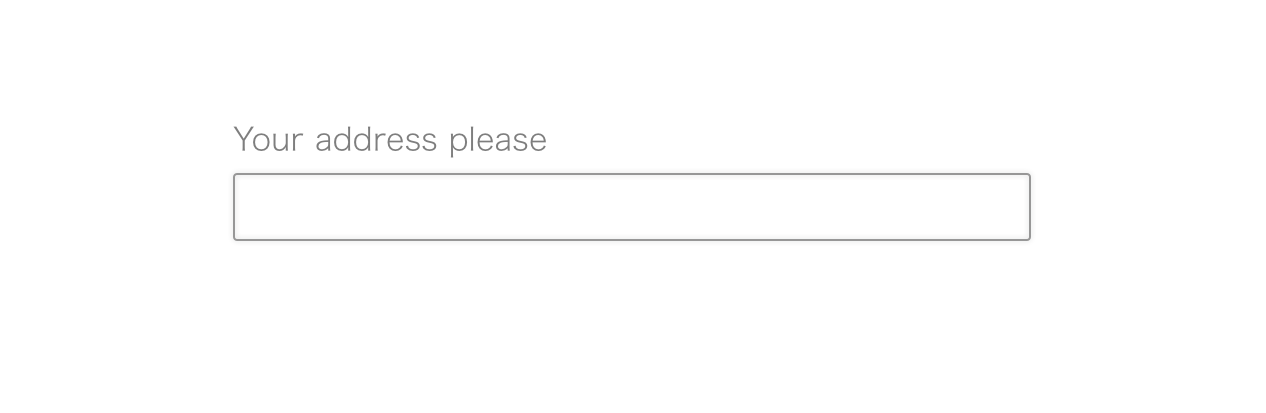
User would type some text and save it to backend. Of course some validation rules, such as not too long or to short, are needed.
A not so simple InputBox
However, from an experienced developer’s perspective, that’s toally a different story. A simple InputBox means something like:
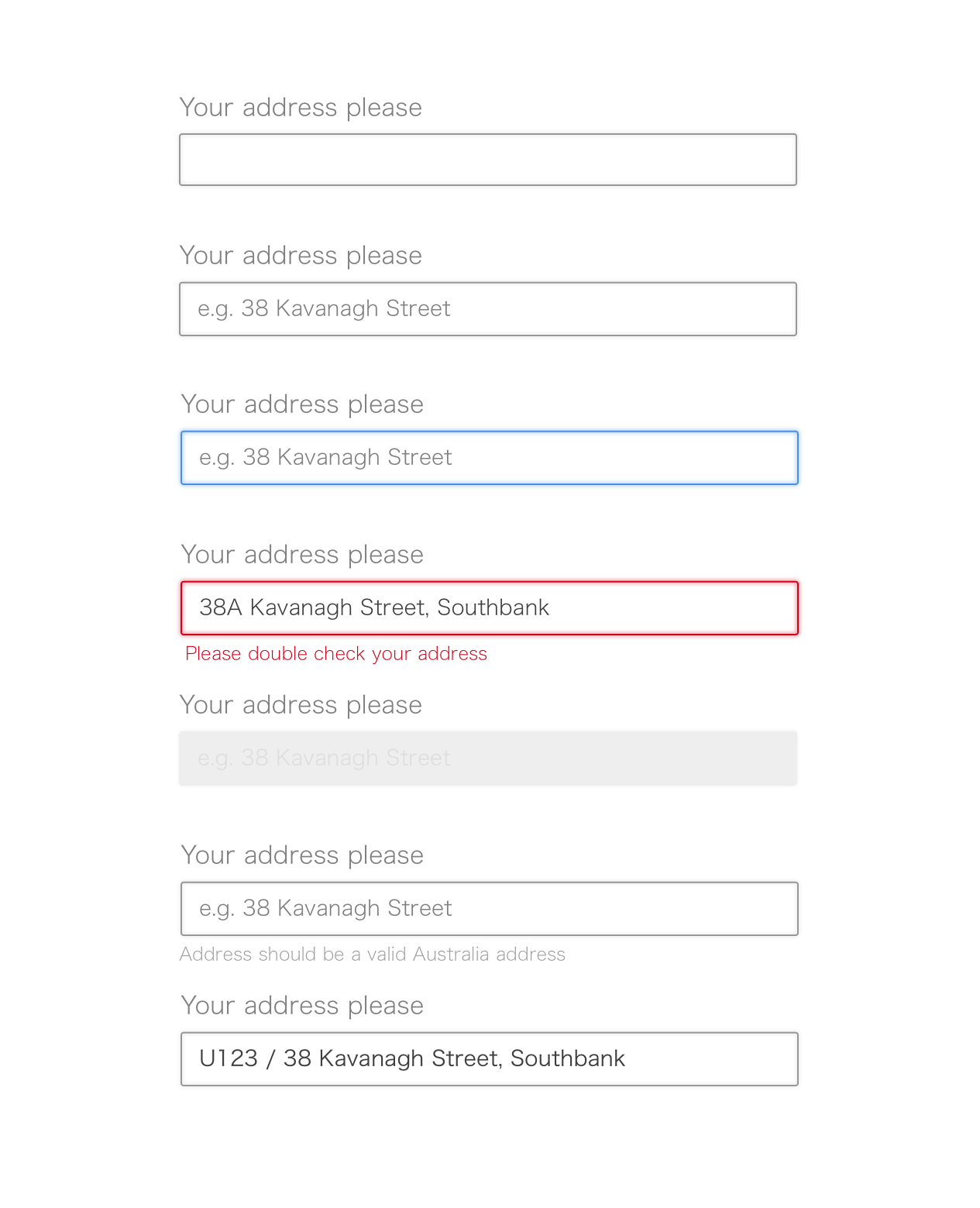
Obviously it has more states thus more complicity:
- disabled
- no content
- fouced
- invalid
- with heloperText
- accessibility
- others
Generally speaking, in the initial state, the InputBox shows a placeholder, when the user starts to typing, a lot of realtime feedback are needed: spelling check, length check, format and so on. Additionally, other part of the page may have impact to current InputBox as well. For example, an unauthorised user is not supposed to type anything so we have to disable it.
Different states mean different UI styles, such as font-size, font-family, color, margin and padding, etc. Those trival details would take many back and forth time which is hard to neglected by most of us during the estimation stage.
Another time consuming work is validation (and define the rules, again, it’s rarely seen the rules can be defined clearly by one round).
Validation
Validation, as a crossing-cut requirement are always being underestimated in projects. Apart from the basic validation rules like length, email address, normally there will be some complicated rules that potentially would break the existing implementation logic.
For instance, when developers came up with a solution for validation like:
const validations = {
minLength: 1,
maxLength: 16,
}
<AddressSearch validations={validations} value={value} />
After some rounds of debuging and refactoring, it works well in the way like:
const builtIns = {
minLength: (value, criteria) => value && value.length > criteria,
maxLength: (value, criteria) => value && value.length < criteria
}
const isValid = (validations) => (value) => {
return _.every(validations, (k, v) => builtIns[k](value, v))
}
const AddressSearch = ({validations, value}) => (<Input error={isValid(validations)(value)} ... />);
All of sudden, next requirement is connect the validation of AddressSearch to another InputBox: when the value in the country Dropdown changed, rules for AddressSearch are changed corespondingly.
Changes like this would break some logics in lot of places, and developer might need more time to apply the changes across the applicaiton, and tests respectively. Code like builtIns in the snippet shows above has to be rewritten.
Restrictions
Along with validation, for some fields, we want to stop user from typing some of the characters (like alphabet only, no whitespace etc). It can be seen as an extension of validation, however, it could be a separate topic.
Some examples might be:
- No special characters allowed
- Only digits
- Only alphabet allowed
- 1-12 as months or 1-31 as days
- Digits and dot
Sometimes those rules are orthogonality but sometimes they might interfere each other.
For example, you want to collect the phone number by provide a InputBox like:
<input type="number" />
However, there is a defect when the user have to provide prefix 0 for state code or something (or maybe +60). And the browser is smart enough to remove the leading 0 for you.
You could do
<input type="tel" pattern="[0-9]*">
to get it fixed. But new issues may be emerging later. In summary, every potential issue and its corresponding solution has its own problem, and it’s normally very difficult for us to foresee those efforts. For experienced developer, yes, and for people playing other roles situation could be even worse.
One more variable
Now I believe PO got a better understanding of how much efforts are needed for a simple InputBox. That’s just a small piece of the iceberg.
Let’s assume that we need to enhance the InputBox a little more: when a user typing address, we have to search the snippet and auto complete the full address.
Whenever network matter is introduced, things turns to be much more complex, the worse part is it’s not linear. On one hand, async system calling itself is unreliable and complicated than you consume local data. On the other hand, there are too many variables that out of your control: network speed, network failure (routing, firewall, etc). Additionally, once you have frontend and backend separation, you need to workout the protocal between both ends. How do you make sure the syncnisation for both sides?
It’s very common to see that UI need something and eventually found that field is not available from backend, or backend saving date as long but frontend needs timezone as a metedata or so.
Some rule apply for validation, you need logic both in UI forms and in backend models and presistence layer. When you’re using isomorphism architecture you might use the same piece of code for both backend and frontend that could relieve the pain. But it’s hard for cases that using different languages in UI and backend - you have to put the same logic in both languages, in both sides. And the problem is, how do you make sure those changes happend in synchornised?
Of course, I believe from the technical point of view, we can eventually find some solutions and some trade-offs for those problems. But you should keep in mind that those things don’t happend for free, they come with some cost.
Even for experienced developers and members who has the willing to keep learning it’s still remains true in most cases. After all, a lot of problems cannot foresee and surely you cannot resolve anything you don’t know yet.
Exceptions - Happy path pitfall
In most cases, people tend to think things in the logic way, the happy path, including estimation too. But in the development stage, the so-called happy path is actually rare, they are abnormal. There are too many factors in the real world that can break our application in the unexpected ways. Network timeout, service downtime, routinely backend service upgrade, incompatible browsers, unmatched operstion system, different hardware and so on.
Since it’s invectable for failing, seems the only option for us as developers is design some concieve protection mechanism. Firstly we need something to recovery the application from a failure (instead of a blank page), secondly we need to record some error information for us to debug or help us to do the further investigation.
Cross functional requirements
Apart from functionility, there are other factors to be considered as well. Such as accessibility and useabliity (like wording on the page to make the experience more smooth), and compatible as well.
Some common cross functional requirements are:
- Cross browsers supporting
- Multiple devices supporting
- *blities
Another thing people keep ingoring is for responsive design, Dev / BA has to work closely with UX to make the sure the design works well on different screens. In most scenarios, the way how a user interactive in tablet is totally different with in desktop, and font-size, animations too.
Beyond technical details
Besides the unpertectable legecy and barrier from the technical prespective, there are some other more time-consuming factors. They are everywhere, trival and tiny for each one, but in accumlation the effort can be significant.
Chaos is normal
Let’s say in a project there are serval Devs, let’s put the name into an array:
const roster = [
'Matt C',
'Santosh',
'Patricia',
'Nicole',
'Juntao'
]
Possibilitely speaking, everybody has to handle something in daily life, such as holiday, sick leave, traffic delay, or lost on the way for coffee.
const execuses = [
'is stuck in traffic',
'is running later',
'has to pick up kid',
'is not feeling very well, take half a day off',
'is having holiday in Hawaii'
]
And life is exactly like the code below:
`${_.shuffle(roster)[0]} ${_.shuffle(execuses)[0]}`
That’s why in the real world, you would see something like this happens everyday:
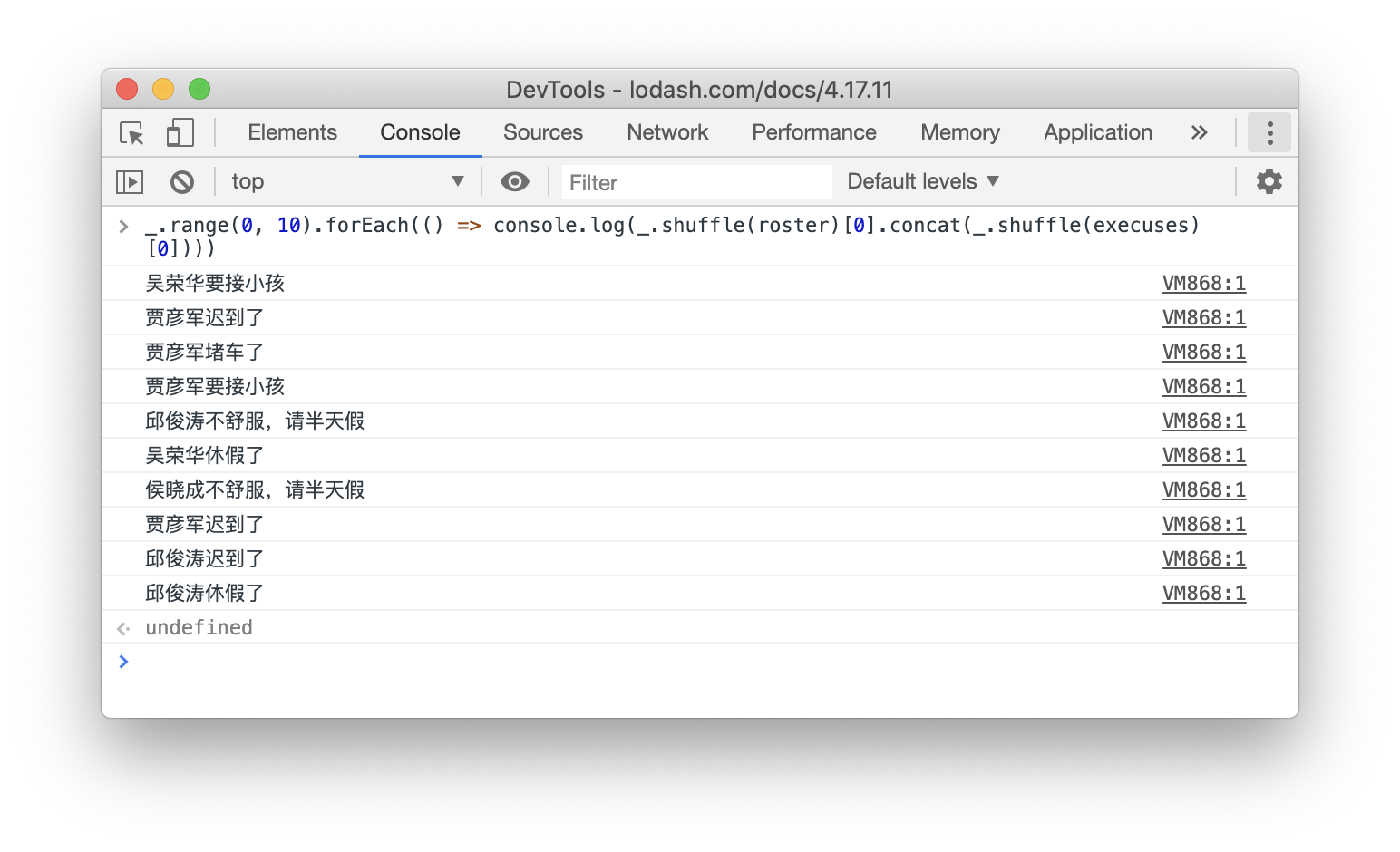
Maybe it’s unlikely happen each day, but in the relatively long run, you could see it happen almost certainly. And it could be worth if there are enough parties in a project, while team gets bigger, the posibility of uncertaint increase as well. And all of sudden, everthing is not working is normal, after all, that’s the world we’re living in.
All of those uncertainty could cause our estimation fail, and surely we cannot see them at the very begining, thus we underestimate.
A little story
Serval years ago in a estimation session, I gave my estimation as 3 days for a RESTful API of a resource, and the tech lead from our client looked pretty unsatisified by that. He told me he could finished it in half a day - it was just a CURD after all.
I helped him to list some of the tasks and he mused after:
- Database migration
- Entity definition
- Relationship between Entities
- Service / Controller
- Exception handling
- Unit tests
- Pact between our system to downstreams
- Integration tests
As far as I could recall, it took at least 3 days, actually just found people we can get information to precede took one day and a half.
How can we handle that
I guess you have already got some of the ideas about how we underestimate ahead of the actual work. To handle this problem, basic princple of course is do exactly opposite as what we would normally do it. In practise, a feasible solution is break the work small enough to reduce the uncertainty, and discovery more details we could not see in higher level.
Such as different states of a InputBox, the transitions between states, styles for each state and so on. During the elabration, details start emerge by themslves. Furthermore, when you have to deal with data fetching, loading, loading failure, no data avaliable are all come and then can drive more uncharted details, which potentially will make the estimation more accurate.
State machine can be used as a manner to enumerate all the possible states of a component or a group of components, that can reveal potentially all the combinition of states and all the variations.
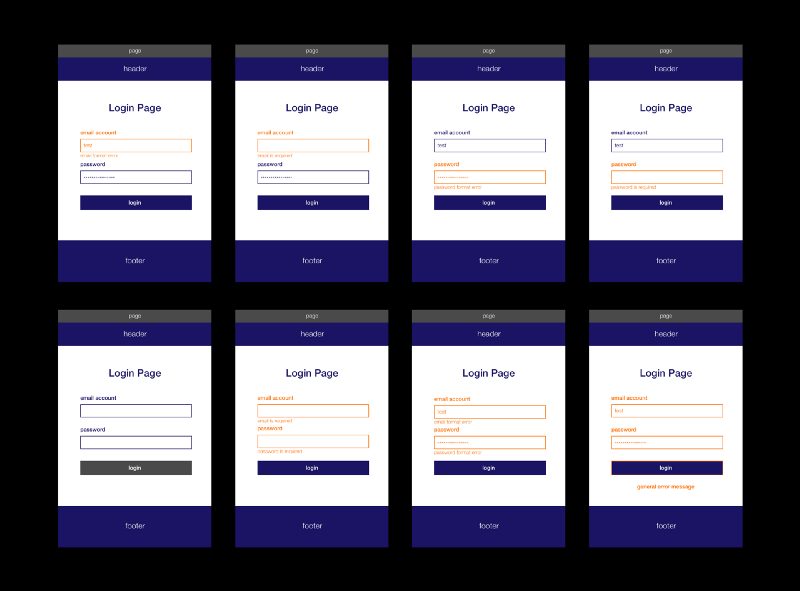
Additionally, in your heart you have to admit the world is complicated, in a large orgnisation things are all mingled together in a super complex way, all of those factor can effect each other and make the in the unpredictable surface. We have to proactively embrace the changes instead of resist it. On the other hand, it drive us to adopt the simple design, solid infrastructure, high quality build method and so on to handle the overall complicity.
Summary
At this point, I suppose you already know what’s happened in delivering the InputBox, and yes, althrough there are some buffer in the estimation, it still took more than 1 week to get it done.
Because of the knowledge barrier and biases, we tend to neleget details which actually impact the effort a lot. Furthermore, we are in a world that is super complicated and full of uncertainter in many ways, different factors are interconnected with each other, and it’s easy for us to loss the objective view to evaluate. If you ignore the uncertainter, you underestimate the actual effort significately.
One way to reduce the chaos is elabrity, thus improve the reliability. The more you break down, the acturate the estimation will be (of course, the break down itself IS effrots as well). On the other hand, we need to embrace the chaos, and build software in a simple and easy-to-change manner to make it more flexible and adjustable.
I planed to write this article in around 3 days, just drawing the graphic took me 2 nights. Drafting and spelling check took me another two, and additionally one more for polishing the language.